

Fundamentos do Apache Kafka e seu Ecossistema Explicado de Maneira Simples – Parte I
Olá, pessoal!
Atendendo a pedidos, vou iniciar uma nova série de artigos focada nos fundamentos e componentes do Apache Kafka utilizando a Confluent Platform.
Meu objetivo é ser o mais didático e claro possível. Se algum ponto não ficar claro, peço que deixem seus comentários para que eu possa aprimorar ainda mais o conteúdo.
Vamos começar ?
O Que é Apache Kafka?
O Apache Kafka é uma plataforma que ajuda diferentes partes de um sistema a enviar e receber dados em tempo real. Esses dados podem ser qualquer coisa — desde leituras de sensores de temperatura até transações financeiras.
Principais Componentes
- Tópicos (Topics): Imagine que os tópicos são caixas de correio, onde os dados são guardados. Cada tipo de dado (como transações ou leituras de temperatura) vai para uma caixa específica.
- Mensagens (Messages): As mensagens são os dados ou eventos que o Kafka entrega. Por exemplo, um sensor de temperatura pode enviar mensagens dizendo qual a temperatura atual.
- Partições (Partitions): Para garantir que o processamento seja rápido, as caixas de correio (tópicos) são divididas em partes menores chamadas partições. Isso permite que o Kafka processe várias mensagens ao mesmo tempo.
- Produtores (Producers): São as “pessoas” que enviam mensagens para as caixas de correio. No caso do Kafka, os produtores são os aplicativos que geram dados e os enviam para o Kafka.
- Consumidores (Consumers): São os aplicativos que retiram as mensagens das caixas de correio e as processam.
Diagrama: Como o Kafka Funciona

O Modo KRaft
Antigamente, o Kafka precisava de um “gerente” externo chamado ZooKeeper para coordenar quem enviava e recebia dados. Com o modo KRaft, o Kafka cuida disso sozinho, usando o algoritmo Raft para garantir que todos os componentes do sistema estejam sincronizados e nenhum dado se perca.
- Controlador (Controller): No modo KRaft, o próprio Kafka tem um “gerente” interno que organiza as partições, réplicas e cuida do estado do sistema.
- Replicações: Para garantir que os dados estejam sempre seguros, o Kafka faz cópias de cada partição (chamadas réplicas) e distribui essas cópias em várias máquinas. Se uma máquina falhar, outra assume, garantindo que os dados não sejam perdidos.
Como Funciona a Gravação de Mensagens no Kafka?

O Líder
Em cada partição, existe um líder. O líder é como o gerente da central de distribuição dos correios, responsável por uma determinada área. Ele decide quem pode enviar uma carta (ou mensagem) para aquela área e quem pode receber as novas entregas.
O Processo de Gravação
- Você escreve uma carta (mensagem): Quando você quer enviar uma mensagem ao Kafka, é como se você estivesse escrevendo uma nova carta.
- A carta vai para a central de distribuição (tópico): Essa carta (mensagem) é enviada para o tópico certo, que funciona como uma central de distribuição específica.
- A carta é entregue na área (partição): O líder da partição recebe a carta e a coloca na fila de entregas da área correta, sempre no final da fila, para ser entregue na ordem de chegada.
Replicação de Dados no Kafka
O Papel do Líder em Cada Broker no Kafka
- O leader: É o broker que possui a cópia mais recente dos dados de uma partição. Ele é o único broker que pode receber novas mensagens para aquela partição.
- As réplicas: São outros brokers que possuem cópias da mesma partição. Eles replicam as mensagens do líder para garantir a alta disponibilidade e tolerância a falhas.
Responsabilidades do Leader
- Receber novas mensagens: É o único broker que pode receber novas mensagens para a partição.
- Gerenciar o processo de replicação: Envia as novas mensagens para as réplicas e garante que elas estejam atualizadas.
- Coordenação de commits: Define quando uma mensagem pode ser considerada como “commitada” e segura.
- Eleição de um novo líder: Caso o líder falhe, ele participa do processo de eleição de um novo líder entre as réplicas.
Por que ter um líder?
- Consistência: Garante que todas as réplicas tenham a mesma sequência de mensagens.
- Alta disponibilidade: Se o líder falhar, uma das réplicas pode assumir o papel de líder, garantindo a continuidade do serviço.
- Escalabilidade: Permite que as mensagens sejam distribuídas por várias partições e replicadas em diferentes brokers.
Em resumo, o líder é o ponto central de controle para uma partição no Kafka. Ele coordena a replicação, garante a consistência dos dados e garante a alta disponibilidade do sistema.
O que é a Confluent Platform?
A Confluent Platform é uma plataforma de streaming de dados que expande as funcionalidades do Apache Kafka para oferecer uma solução mais completa e pronta para empresas. Ela adiciona recursos e ferramentas que facilitam a implementação, o gerenciamento e o uso do Kafka em ambientes de produção.
Aqui estão as melhorias principais que a Confluent Platform oferece:
- Kafka Connect: Permite integrar Kafka com outros sistemas facilmente, como bancos de dados, sistemas de mensagens ou serviços em nuvem, usando conectores pré-construídos (como Oracle, MongoDB, AWS S3, etc.).
- ksqlDB: Uma ferramenta de processamento de stream que permite executar consultas SQL em tempo real sobre dados em Kafka, facilitando a transformação e análise dos fluxos de dados sem precisar escrever código complexo.
- Confluent Control Center: Uma interface gráfica que oferece uma visão geral da plataforma, permitindo monitorar e gerenciar o Kafka e os tópicos, verificar desempenho, saúde do cluster, e acompanhar o fluxo de dados em tempo real.
- Segurança: A Confluent Platform adiciona recursos avançados de segurança, como autenticação via SASL/SSL, autorização com ACLs e criptografia de dados em trânsito e em repouso.
- Confluent Schema Registry: Um repositório centralizado para gerenciar e validar esquemas de dados (como Avro, JSON ou Protobuf) usados pelos produtores e consumidores de Kafka, garantindo que a compatibilidade de dados seja mantida ao longo do tempo.
O Ecossistema Kafka
Além de ser um sistema de mensagens, o Kafka possui várias ferramentas que facilitam o trabalho de integração, processamento e gerenciamento de dados em tempo real.
Kafka Connect: Conectando Sistemas Externos
O Kafka Connect funciona como uma ponte que conecta o Kafka a outros sistemas, como bancos de dados, arquivos e até outros aplicativos. A mágica do Kafka Connect está nos conectores, que permitem integrar o Kafka com uma infinidade de fontes e destinos de dados sem que você precise escrever muito código. Vamos explorar três exemplos práticos:
Exemplos de Conectores
- Conectores para Replicação de Dados em Bancos de Dados: Se você possui um banco de dados Oracle e deseja replicar suas transações em tempo real para o Kafka, você pode usar um conector de banco de dados como o JDBC Source Connector ou Debezium CDC (entre outros). Esses conectores capturam todas as alterações nas tabelas e as envia para o Kafka em forma de mensagens.
Exemplo: Pense em um sistema de banco de dados Oracle que guarda transações de clientes. O Kafka Connect pode puxar esses dados e colocá-los diretamente em um tópico Kafka. - Conectores para Leitura de Arquivos de Texto: Suponha que você tenha um arquivo de log que é atualizado constantemente e deseja enviar esses dados para o Kafka para que sejam processados em tempo real. Nesse caso, você pode usar o FileSource Connector, que lê os dados do arquivo e os envia para um tópico no Kafka.
Exemplo: Imagine que sua aplicação salva dados de sensores em um arquivo de texto que é atualizado a cada segundo. O Kafka Connect pode monitorar esse arquivo e enviar as novas linhas para o Kafka. - Conectores para Integração com Outros Sistemas: Para integrar o Kafka com sistemas como o ElasticSearch ou o MongoDB, você pode usar conectores de destino. Por exemplo, ao enviar logs de transações para um tópico Kafka, você pode configurar um ElasticSearch Sink Connector para armazenar e indexar essas transações automaticamente no ElasticSearch.
Exemplo: Quando o Kafka recebe mensagens de transações financeiras, você pode usar um conector para enviá-las diretamente ao ElasticSearch, onde elas podem ser indexadas para buscas.
Diagrama: Kafka Connect (Conectores)

Esses são apenas alguns exemplos dos muitos conectores que o Kafka Connect oferece, tornando fácil integrar o Kafka com quase qualquer sistema que você estiver utilizando.
ksqlDB: Consultas em Tempo Real
Com o ksqlDB, você pode transformar dados e fazer consultas em tempo real dentro do Kafka usando uma linguagem parecida com o SQL. Isso significa que você pode processar os dados sem escrever código complexo.
Exemplo:
Imagine que você tem dados de temperatura chegando de várias regiões. Com o ksqlDB, você pode calcular a temperatura média por região em tempo real e enviar esse resultado para outro tópico.
SELECT region, AVG(temperature)
FROM temp-data
GROUP BY region;Diagrama: ksqlDB Processando Dados

Apache Flink: Processamento em Fluxo com Flexibilidade
O Apache Flink é uma ferramenta que não faz parte do Kafka diretamente, mas é cada vez mais utilizada junto ao Kafka por sua capacidade avançada de processamento em tempo real. Assim como o Kafka Streams e o ksqlDB, o Flink processa fluxos de dados, mas é mais poderoso quando se trata de processamento em larga escala e operações complexas. O Flink pode fazer análises em janelas de tempo, detectar padrões e executar operações de machine learning em dados que chegam via Kafka.
Exemplo:
Suponha que você esteja monitorando leituras de temperatura de diferentes sensores e deseja detectar se a temperatura em uma região específica aumenta rapidamente em um curto espaço de tempo. O Flink pode analisar esses dados em janelas de tempo e enviar alertas se houver picos súbitos.
SELECT
region_id,
MAX(temperature) AS max_temperature,
CASE
WHEN MAX(temperature) > 100 THEN 'ALERT'
ELSE 'NORMAL'
END AS status
FROM TABLE(
TUMBLE(TABLE temp_data, DESCRIPTOR(event_time), INTERVAL '5' MINUTE)
)
GROUP BY
region__id;Diagrama: Flink Analisando Dados de Sensores em Tempo Real

O Flink pode ser usado para casos mais complexos de processamento de dados em tempo real, como detecção de fraudes, agregação de grandes volumes de dados e muito mais.
Kafka Streams API: Aplicativos que Processam Dados
A Kafka Streams API é uma ferramenta que permite criar aplicativos que processam dados em tempo real. Diferente do ksqlDB, que usa uma linguagem mais simples, a Kafka Streams API oferece mais flexibilidade para criar aplicativos complexos.
Exemplo:
Você pode criar um aplicativo que monitora transações bancárias em tempo real e detecta compras suspeitas, tomando ações automáticas quando algo parece fora do normal.
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.kstream.*;
import java.time.Duration;
import java.util.Properties;
public class TransactionMonitorApp {
public static void main(String[] args) {
// Configurações do Kafka Streams
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "customer-transactions");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
StreamsBuilder builder = new StreamsBuilder();
// Fonte do stream: tópico de transações de cartão de crédito
KStream<String, String> transactions = builder.stream("credit-card-transactions");
// Valor mínimo para filtrar transações acima de X (exemplo: 100.00)
double transactionThreshold = 100.00;
// Fase 1: Filtragem - Transações acima de um valor X
KStream<String, Transaction> filteredTransactions = transactions
.mapValues(TransactionMonitorApp::parseTransaction) // Converte a string JSON em objeto Transaction
.filter((key, transaction) -> transaction.getAmount() > transactionThreshold); // Filtra transações acima do valor X
// Fase 2: Agregação - Contagem de transações por cartão em uma janela de 5 minutos
KTable<Windowed<String>, Long> transactionCounts = filteredTransactions
.groupByKey() // Agrupa as transações por card_id (chave)
.windowedBy(TimeWindows.of(Duration.ofMinutes(5))) // Aplica uma janela de 5 minutos
.count(); // Conta as transações por cartão dentro da janela
// Fase 3: Detecção de Anomalias - Comparação com o perfil de compras esperado
KStream<String, String> anomalies = transactionCounts
.toStream()
.filter((windowedKey, count) -> isAnomaly(windowedKey.key(), count)) // Detecta anomalias com base no perfil esperado
.map((windowedKey, count) -> KeyValue.pair(windowedKey.key(), "Anomaly Detected for card: " + windowedKey.key() + " with " + count + " transactions in 5 minutes"));
// Saída - As anomalias são enviadas para o tópico "suspicious-transactions"
anomalies.to("suspicious-transactions");
// Inicia a aplicação Kafka Streams
KafkaStreams streams = new KafkaStreams(builder.build(), props);
streams.start();
// Adiciona shutdown hook para parar a aplicação corretamente
Runtime.getRuntime().addShutdownHook(new Thread(streams::close));
}
// Método para converter a string JSON em um objeto Transaction
public static Transaction parseTransaction(String transactionJson) {
// Aqui você deve implementar a lógica de parsing do JSON para o objeto Transaction
// Exemplo simplificado: utilizando uma biblioteca como Jackson ou Gson
return new Transaction("1234567890", 150.00, "2024-10-08T10:15:30Z", "store-123");
}
// Método para detectar se há uma anomalia com base no número de transações e um perfil esperado
public static boolean isAnomaly(String cardId, long transactionCount) {
// Aqui você implementa a lógica de comparação com o perfil de compra do cartão
// Exemplo simples: se o número de transações for maior que 5, consideramos uma anomalia
return transactionCount > 5; // Exemplo de regra de anomalia
}
// Classe para representar uma transação
public static class Transaction {
private String cardId;
private double amount;
private String timestamp;
private String location;
public Transaction(String cardId, double amount, String timestamp, String location) {
this.cardId = cardId;
this.amount = amount;
this.timestamp = timestamp;
this.location = location;
}
public String getCardId() {
return cardId;
}
public double getAmount() {
return amount;
}
public String getTimestamp() {
return timestamp;
}
public String getLocation() {
return location;
}
}
}Diagrama: Kafka Streams API Processando Transações

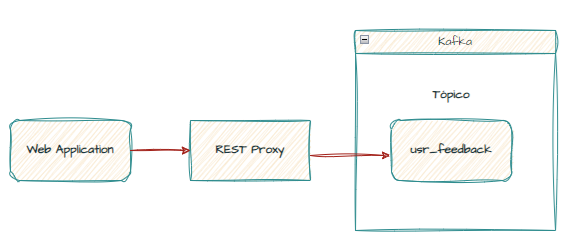
Kafka REST Proxy: Envio de Mensagens via HTTP
O Kafka REST Proxy é útil quando você tem um sistema que não pode se conectar diretamente ao Kafka. Ele permite enviar e receber mensagens do Kafka usando requisições HTTP.
Exemplo:
Se você tem um aplicativo web onde os usuários enviam feedback, o REST Proxy pode pegar esses dados e enviá-los diretamente para o Kafka.
curl -X POST http://localhost:5000/feedback \
-H "Content-Type: application/json" \
-d '{"user": "johndoe", "feedback": "Ótimo serviço!"}'Diagrama: Kafka REST Proxy
Kafka Schema Registry: Gerenciando Formatos de Dados
O Schema Registry garante que todas as mensagens enviadas ao Kafka sigam um formato consistente, evitando que dados incompatíveis sejam enviados. Isso é especialmente útil quando diferentes sistemas estão produzindo dados que precisam seguir o mesmo formato.
Exemplo:
Se vários sistemas estão enviando feedback de usuários, o Schema Registry assegura que todos sigam o mesmo esquema, evitando erros ao ler esses dados.
{
"type": "record",
"name": "UserFeedback",
"fields": [
{
"name": "user",
"type": "string"
},
{
"name": "feedback",
"type": "string"
}
]
}Diagrama: Kafka com Schema Registry

Próximos passos
Agora que já apresentei uma visão geral sobre o Apache Kafka na Confluent Platform, seus componentes e o Apache Flink, nos próximos artigos vamos explorar cada um deles com mais profundidade.
Vamos mergulhar nos detalhes técnicos, entender como funcionam, como se integram e quais são as melhores práticas para utilizá-los de forma eficiente em cenários reais. O objetivo é proporcionar um entendimento mais sólido dessas tecnologias, tornando o aprendizado mais completo e aplicável no dia a dia.
Até lá !
Referências

Estou acompanhando os seus textos e tenho gostado muito.
Gostaria de dar uma idéia sobre um novo artigo. Você poderia escrever sobre o Kafka na Cloud?
Abs
Como vai Mendes ? Tudo bem ?
Obrigado pela dica. Assim que eu terminar essa série, irei começar um sobre a Confluent Cloud.
Legal!
Fico feliz que gostou ! 🙂
Bora aprender esse kafka