
Oracle Data Pump Export – PARALLEL COMPRESSION
Seria chover no molhado dizer que o Data Pump é uma ferramenta que permite a movimentação de dados e esquemas entre bancos de dados. O objetivo deste artigo é trazer luz aos parâmetros PARALLEL e COMPRESSION.
Vamos usar a analogia de uma cozinha para entender melhor. Imagine que você está organizando um grande jantar. Você tem uma série de pratos para preparar e quer garantir que tudo seja feito da maneira mais eficiente possível.
PARALLEL no Oracle Data Pump é como ter uma equipe de chefs trabalhando simultaneamente em diferentes pratos. Cada chef (ou processo) trabalha em uma tarefa específica ao mesmo tempo, aumentando a eficiência e a velocidade com que os pratos (ou dados) são preparados e servidos. Em termos técnicos, PARALLEL permite que múltiplas tarefas de leitura e escrita sejam executadas simultaneamente, utilizando múltiplos processos em paralelo.
COMPRESSION no Oracle Data Pump é como embalar esses pratos de forma que ocupem menos espaço, facilitando o transporte. Ao aplicar a compressão, você reduz o tamanho dos arquivos de dump gerados durante a exportação. Isso economiza espaço em disco e reduz o tempo de transferência dos arquivos. A compressão pode ser aplicada a dados, metadados ou ambos.
Para que os jobs sejam concluídos mais rapidamente, podemos aumentar o número de processos DWnn trabalhando em paralelo, através do parâmetro PARALLEL. Quando não especificado, o job conta com apenas um processo DWnn para executar a operação. Quando configurado com dois ou mais processos, cada um deles escreverá em um dump file, necessitando que no nome do dump file seja especificado um dos placeholders %U ou %L.
Ao aplicar o parâmetro COMPRESSION, precisamos respeitar suas características:
- ALL: Comprime todos os dados e metadados;
- METADATA_ONLY: Comprime apenas os metadados (default);
- DATA_ONLY: Comprime apenas os dados;
- NONE: Desabilita a compressão dos dados e dos metadados.
Exemplo de Exportação com Compressão
expdp my_user/my_password@my_database SCHEMAS=MY_SCHEMA COMPRESSION=ALL directory=my_dump_dir dumpfile=my_schema.dmp logfile=my_schema_exp.logEsta é a sintaxe que usarei na prática de hoje
expdp system/senha@orclpdb full=y PARALLEL = 2 COMPRESSION=ALL compression_algorithm = medium directory = my_dir dumpile = dump_15_parcompression_%u.dmpAo aplicar o parâmetro COMPRESSION_ALGORITHM, precisamos respeitar suas características:
BASIC: Oferece uma boa combinação entre a taxa de compressão e velocidade (default).
LOW: Tem pouco impacto no throughput da operação. É utilizado quando recursos de CPU são um fator limitante.
MEDIUM: Recomendado para a maioria dos ambientes. Assim como o algoritmo BASIC, provê uma boa combinação de taxa de compressão e velocidade.
HIGH: Só é recomendado em cenários onde o dump file comprimido irá trafegar através de uma rede lenta, onde o fator limitante é a velocidade da rede.
Monitorando a Compressão
Podemos monitorar o progresso da exportação e verificar o tamanho dos arquivos de dump comprimidos para garantir que a compressão está funcionando conforme esperado, com o comando:
ls -lh /path/to/directory/my_schema.dmpSegue o detalhe da sintaxe abaixo:
[expdp system/senha@orclpdb]: Conectando ao banco com o usuário system.
[FULL=Y]: Indica que será um Data Pump completo.
[PARALLEL=2]: Este é o termo chave para o exercício de hoje, indicando o número de processos paralelos.
[COMPRESSION=ALL]: Indica que serão exportados os dados e os metadados.
[COMPRESSION_ALGORITHM=MEDIUM]: A documentação da Oracle recomenda o uso do parâmetro MEDIUM, lembrando que compressões acima de MEDIUM necessitam do licenciamento da opção Oracle Advanced Compression.
[DIRECTORY=my_dir]: Determina o diretório.
[LOGFILE=log_parcompression.log]: Determina o nome do log.
[DUMPFILE=dump_15_parcompression_%u.dmp]: Define o nome dos arquivos de dump. Depois de toda a teoria, bora pôr a mão na massa!
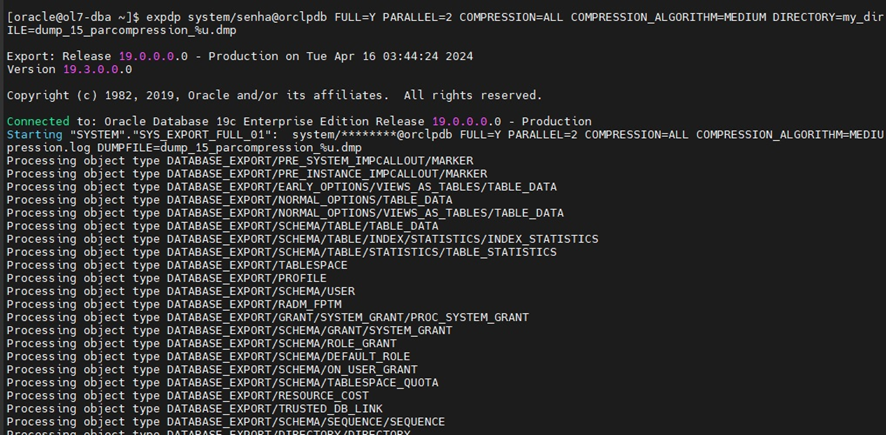
Acima, percebemos a ação com seus detalhes. Como solicitamos ALL na sintaxe, a exportação será completa. No entanto, cabe uma ressalva quanto ao uso do PARALLEL. Existem algumas restrições que precisamos considerar, como:
- Para a exportação de uma tabela ou partição de tabela, é preciso ter a role DATAPUMP_EXP_FULL_DATABASE.
- Metadados de transportable tablespaces não podem ser exportados em paralelo.
- Metadados não podem ser exportados em paralelo com o parâmetro NETWORK_LINK.
Assim, nem todos os objetos são suportados pelo PARALLEL: TRIGGER, VIEW, OBJECT_GRANT, SEQUENCE, CONSTRAINT e REF_CONSTRAINT. Feitas as ressalvas, segue o banquete.
Assim como em um grande jantar, onde alguns pratos específicos exigem cuidados especiais e técnicas diferenciadas, o uso do PARALLEL no Oracle Data Pump tem suas limitações e requer atenção. No entanto, quando aplicado corretamente, oferece uma maneira poderosa de otimizar suas operações de exportação e importação de dados.
Prepare-se para aplicar essas técnicas na prática e veja como elas podem transformar a eficiência do seu ambiente Oracle. Assim como em uma cozinha bem organizada, onde cada chef conhece seu papel e suas ferramentas, você estará pronto para aproveitar ao máximo as capacidades do Oracle Data Pump com PARALLEL e COMPRESSION.
ps aux | grep dw
Com o comando ps aux | grep dw, durante a exportação, conseguimos visualizar o trabalho do PARALLEL=2 conforme configurado na sintaxe acima. Vamos supor que você deseja exportar um esquema com várias tabelas grandes. Você pode usar a opção PARALLEL para dividir a tarefa entre múltiplos processos.
expdp my_user/my_password@my_database schemas=my_schema PARALLEL=2 directory=my_dump_dir dumpfile=my_schema_%u.dmp logfile=my_schema_exp.logEsta é a sintaxe que usarei na prática de hoje
expdp system/senha@orclpdb full=y PARALLEL = 2 COMPRESSION=ALL compression_algorithm = medium directory = my_dir dumpile = dump_15_parcompression_%u.dmpVamos imaginar que estamos em uma grande cozinha profissional, onde cada chef tem uma tarefa específica. O uso do PARALLEL é como se contratássemos mais chefs para ajudar na preparação do banquete. Isso não só acelera o processo, mas também garante que cada prato seja preparado com mais eficiência.
A imagem acima, com uma seta indicando o nível de processamento, mostra 98% de utilização – um exemplo claro de como o paralelismo está otimizando nosso desempenho. Aqui, o hardware é o fator limitante, assim como o espaço físico em uma cozinha pode limitar o número de chefs que podem trabalhar simultaneamente.
Com essas técnicas, você pode garantir que seus dados sejam exportados de forma rápida e eficiente, aproveitando ao máximo os recursos disponíveis. Agora, estamos prontos para aplicar todo esse conhecimento na prática e colher os benefícios de uma operação de exportação bem-sucedida.
lscpu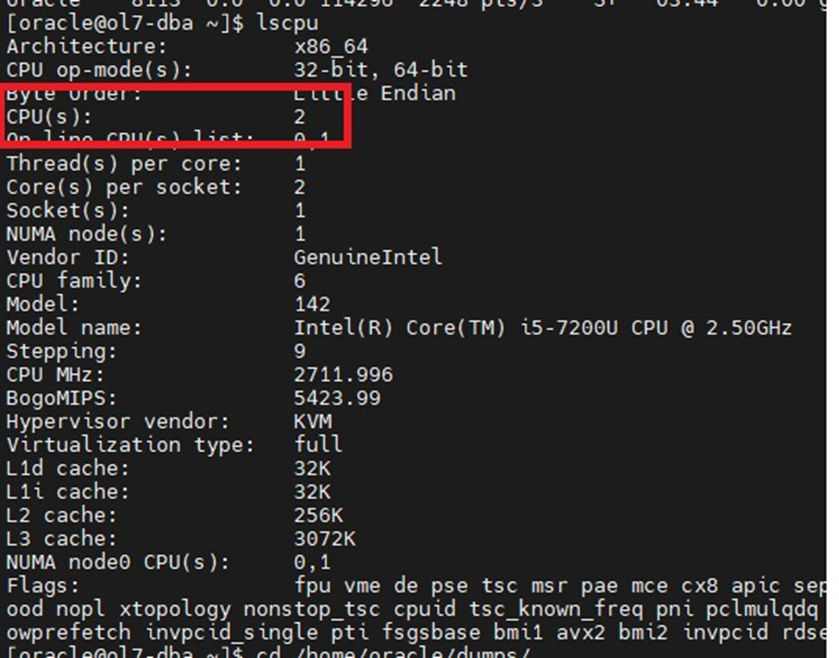
Com o comando `lscpu`, visualizamos que meu laboratório possui 2 núcleos de CPU. Este é o fator limitante: cada CPU assume o processamento e ficará dedicada a esta exportação. Fica aqui o alerta que não é possível configurar um número de processos acima do número de CPUs do seu ambiente.
A opção COMPRESSION no Oracle Data Pump é uma ferramenta útil para gerenciar o tamanho dos arquivos de dump e economizar espaço em disco. É importante escolher o tipo de compressão adequado com base em suas necessidades de performance e armazenamento.
Usar a opção PARALLEL no Oracle Data Pump pode proporcionar ganhos significativos de performance ao dividir a carga de trabalho entre múltiplos processos. É uma ferramenta essencial para operações de exportação e importação de grandes volumes de dados. No entanto, é importante ajustar o valor de PARALLEL de acordo com os recursos do sistema e monitorar a operação para garantir que ela esteja executando eficientemente.
Assim como um chef que se deleita em compartilhar suas receitas, fico contente em dividir essas técnicas valiosas com vocês. Que essa jornada pelo universo do Oracle Data Pump, com seus ingredientes de PARALLEL e COMPRESSION, tenha sido tão saborosa quanto um banquete bem preparado.
Terei o prazer de expandir minhas conexões, compartilhar e somar conhecimentos. Aguardarei seu contato e estou à disposição para qualquer dúvida ou troca de experiências.

Gostei. Valeu!